Accessing CEFI Cloud data with R#
This example requires you to have used conda or mamba to install the cefi-cookbook-dev environment as explained here.
The following notebook is a quick demostration on how to use R to access the CEFI Cloud data. This is designed for users that prefer the programing interface to be R. There are already couple of great resource related to preprocessing and visualizing data in R. Therefore, the notebook will not repeat that part of the code but focusing on how to accessing the data from a R interface. The resources is listed below
http://cran.nexr.com/web/packages/rerddap/vignettes/Using_rerddap.html (A detail introduction of rerddap package and show the visualization in many different datasets)
https://ioos.github.io/ioos_code_lab/content/code_gallery/data_access_notebooks/2017-08-01-xtractoR.html (use a different package called xtractomatic to access the ERDDAP data)
On this page, we will explore the process of extracting a subset of model simualtion data produce from the regional MOM6 model. The model output is to support the Changing Ecosystem and Fishery Initiative. We will showcase how to utilize xarray and fsspec for accessing the data and visualize it on an detailed map. The currently available data can be viewed on
The contents of this folder encompass hindcast simulations derived from the regional MOM6 model spanning the years 1993 to 2019.
Launch R in Jupyterlab
In addition to the standard R code demonstrated below, our current interface leverages JupyterLab to execute R code using the R kernel. To enable this functionality, we utilize the environment.yml file to create a Conda/Mamba environment. The primary objective is to install the r-irkernel package within this environment.This installation of r-irkernel through Conda/Mamba ensures that the R kernel becomes available as an option when launching JupyterLab. Selecting the R kernel empowers users to utilize the JupyterLab interface for running R code effortlessly.
Packages used#
In this example, we are going to use the reticulate library with Python to read the CEFI data into an R data structure.
From there you can operate on the data in R (or R Studio) as you would any other data.
N.B. The only library you need to read the data is the retiuclate library to access the python environment to read the data.
The other libraries are used to filter the data and make a plot on a detailed base map.
The last line show the python configuration that should have been set up when you loaded the conda environment to run this notebook.
library(reticulate)
library(dplyr)
library(maps)
library(ggplot2)
# reticulate::py_config() # check python version
Attaching package: ‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
use_condaenv('cefi-cookbook-dev')
Get some python tools to read the data from the cloud storage#
fsspec and xarray are python packages that are in the conda environment we build to run this notebook. We’re going to import them into our R environment and use them to create a pandas dataframe with lat,lon,tos as the columns
xr <- import('xarray')
fsspec <- import('fsspec')
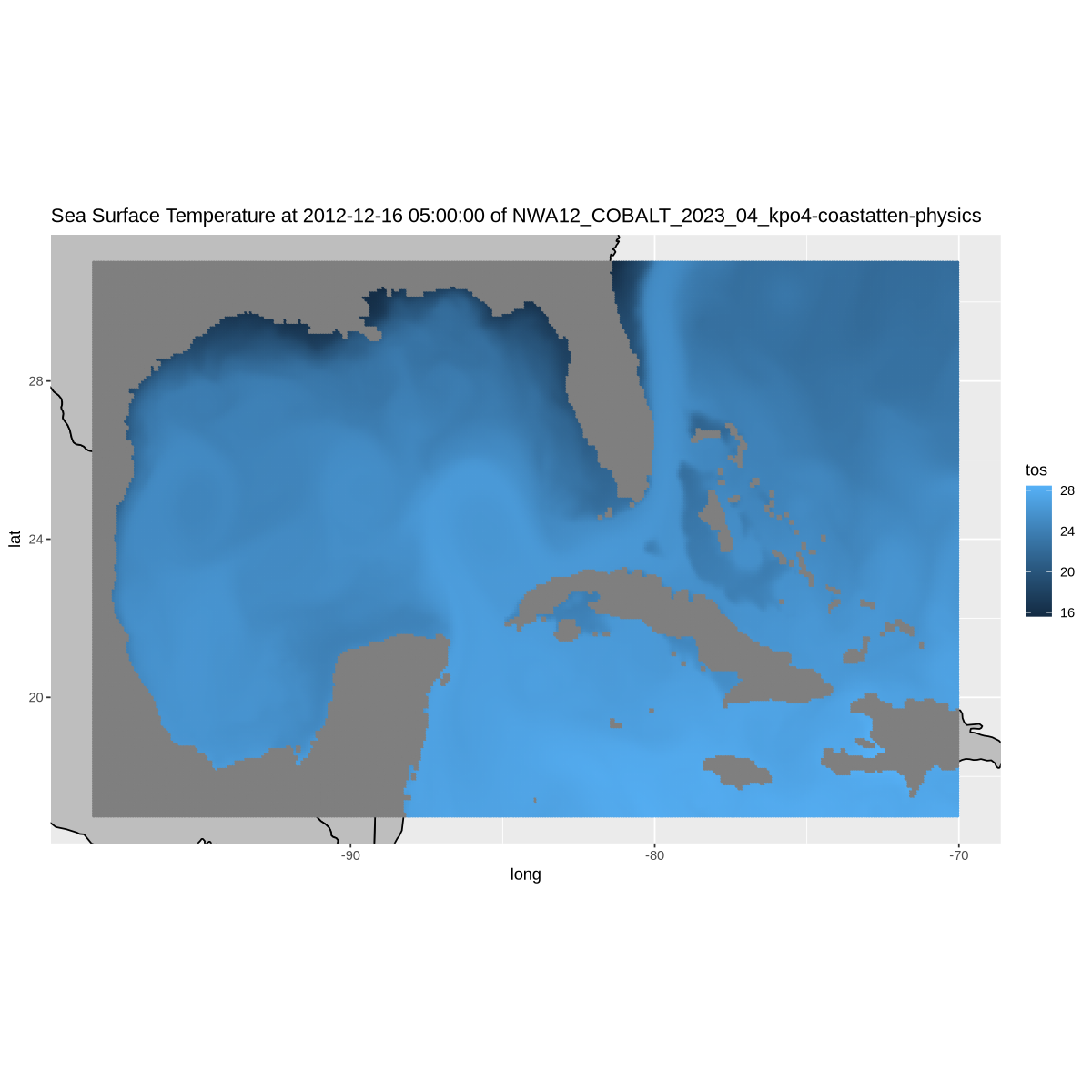
Get some data from the cloud#
Read the data
select a time slice
fs <- fsspec$filesystem('reference',
remote_protocol='gcs',
fo='gcs://noaa-oar-cefi-regional-mom6/northwest_atlantic/full_domain/hindcast/monthly/regrid/r20230520/tos.nwa.full.hcast.monthly.regrid.r20230520.199301-201912.json'
)
m <- fs$get_mapper()
dataset <- xr$open_dataset(m, engine='zarr', consolidated=FALSE)
subset <- dataset$sel(time='2012-12')
Get the variable long_name, date of the slice and data set title for the plot below
datetime <- subset$time$values
title <- subset$attrs$title
long_name <- subset$tos$attrs$long_name
Reorganize that data into a data.frame#
We transform the gridded data into column data with lon, lat, tos as columns. Take care: We are expanding along lon first and then by lat, so we reorder the xarray so that lon varies fastest to match.
subset <- subset$transpose('lon','lat','time')
df <- expand.grid(x = subset$lon$values, y=subset$lat$values)
data <- as.vector(t(matrix(subset$tos$values)))
df$Data <- data
names(df) <- c("lon", "lat", "tos")
Subset the dataset#
We use filter to extract the points over the Gulf region.
df_gulf = filter(df, lat>17)
df_gulf = filter(df_gulf, lat<31)
df_gulf = filter(df_gulf, lon>260)
df_gulf = filter(df_gulf, lon<290)
df_gulf
| lon | lat | tos |
|---|---|---|
| <dbl[1d]> | <dbl[1d]> | <dbl> |
| 261.5577 | 17.00457 | NaN |
| 261.6384 | 17.00457 | NaN |
| 261.7191 | 17.00457 | NaN |
| 261.7998 | 17.00457 | NaN |
| 261.8804 | 17.00457 | NaN |
| 261.9611 | 17.00457 | NaN |
| 262.0418 | 17.00457 | NaN |
| 262.1225 | 17.00457 | NaN |
| 262.2031 | 17.00457 | NaN |
| 262.2838 | 17.00457 | NaN |
| 262.3645 | 17.00457 | NaN |
| 262.4452 | 17.00457 | NaN |
| 262.5258 | 17.00457 | NaN |
| 262.6065 | 17.00457 | NaN |
| 262.6872 | 17.00457 | NaN |
| 262.7679 | 17.00457 | NaN |
| 262.8485 | 17.00457 | NaN |
| 262.9292 | 17.00457 | NaN |
| 263.0099 | 17.00457 | NaN |
| 263.0906 | 17.00457 | NaN |
| 263.1713 | 17.00457 | NaN |
| 263.2519 | 17.00457 | NaN |
| 263.3326 | 17.00457 | NaN |
| 263.4133 | 17.00457 | NaN |
| 263.4940 | 17.00457 | NaN |
| 263.5746 | 17.00457 | NaN |
| 263.6553 | 17.00457 | NaN |
| 263.7360 | 17.00457 | NaN |
| 263.8167 | 17.00457 | NaN |
| 263.8973 | 17.00457 | NaN |
| ⋮ | ⋮ | ⋮ |
| 287.6160 | 30.99516 | 22.10050 |
| 287.6966 | 30.99516 | 22.11896 |
| 287.7773 | 30.99516 | 22.13621 |
| 287.8580 | 30.99516 | 22.15041 |
| 287.9387 | 30.99516 | 22.16084 |
| 288.0194 | 30.99516 | 22.16887 |
| 288.1000 | 30.99516 | 22.17518 |
| 288.1807 | 30.99516 | 22.18109 |
| 288.2614 | 30.99516 | 22.18618 |
| 288.3421 | 30.99516 | 22.19002 |
| 288.4227 | 30.99516 | 22.19225 |
| 288.5034 | 30.99516 | 22.19283 |
| 288.5841 | 30.99516 | 22.19231 |
| 288.6648 | 30.99516 | 22.19145 |
| 288.7454 | 30.99516 | 22.19104 |
| 288.8261 | 30.99516 | 22.19171 |
| 288.9068 | 30.99516 | 22.19394 |
| 288.9875 | 30.99516 | 22.19798 |
| 289.0681 | 30.99516 | 22.20489 |
| 289.1488 | 30.99516 | 22.21741 |
| 289.2295 | 30.99516 | 22.24266 |
| 289.3102 | 30.99516 | 22.28262 |
| 289.3908 | 30.99516 | 22.31960 |
| 289.4715 | 30.99516 | 22.33831 |
| 289.5522 | 30.99516 | 22.34284 |
| 289.6329 | 30.99516 | 22.34084 |
| 289.7135 | 30.99516 | 22.33542 |
| 289.7942 | 30.99516 | 22.32747 |
| 289.8749 | 30.99516 | 22.31860 |
| 289.9556 | 30.99516 | 22.30894 |
Longitude Manipulation#
The model lons are from 0 to 360, so we’re going to use this function to normalize them to -180 to 180 The map polygons are defined on -180 to 180 we need to adjust our values to see them on the map
normalize_lon <- function(x) {
quotient <- round(x / 360.)
remainder <- x - (360. * quotient)
# Adjust sign if necessary to match IEEE behavior
if (sign(x) != sign(360.) && remainder != 0) {
remainder <- remainder + sign(360.) * 360.
}
return(remainder)
}
df_gulf$lon <- unlist(lapply(df_gulf$lon, normalize_lon))
Plot setup#
Set up a resonable plot size and limits for the plot area of the world base map
options(repr.plot.width = 10, repr.plot.height = 10)
ylim <- c( min(df_gulf$lat), max(df_gulf$lat) )
xlim <- c( min(df_gulf$lon), max(df_gulf$lon) )
Mesh/Dot Map#
Plot a mesh/dot colored according to the value of tos at each lat/lon location in the Gulf.
w <- map_data( 'world', ylim = ylim, xlim = xlim )
p = ggplot() +
geom_polygon(data = w, aes(x=long, y = lat, group = group), fill = "grey", color = "black") +
coord_fixed(1.3, xlim = xlim, ylim = ylim) +
geom_point(data = df_gulf, aes(color = tos, y=lat, x=lon), size=.5) +
labs(title = paste(long_name, 'at', datetime, 'of', title))
p
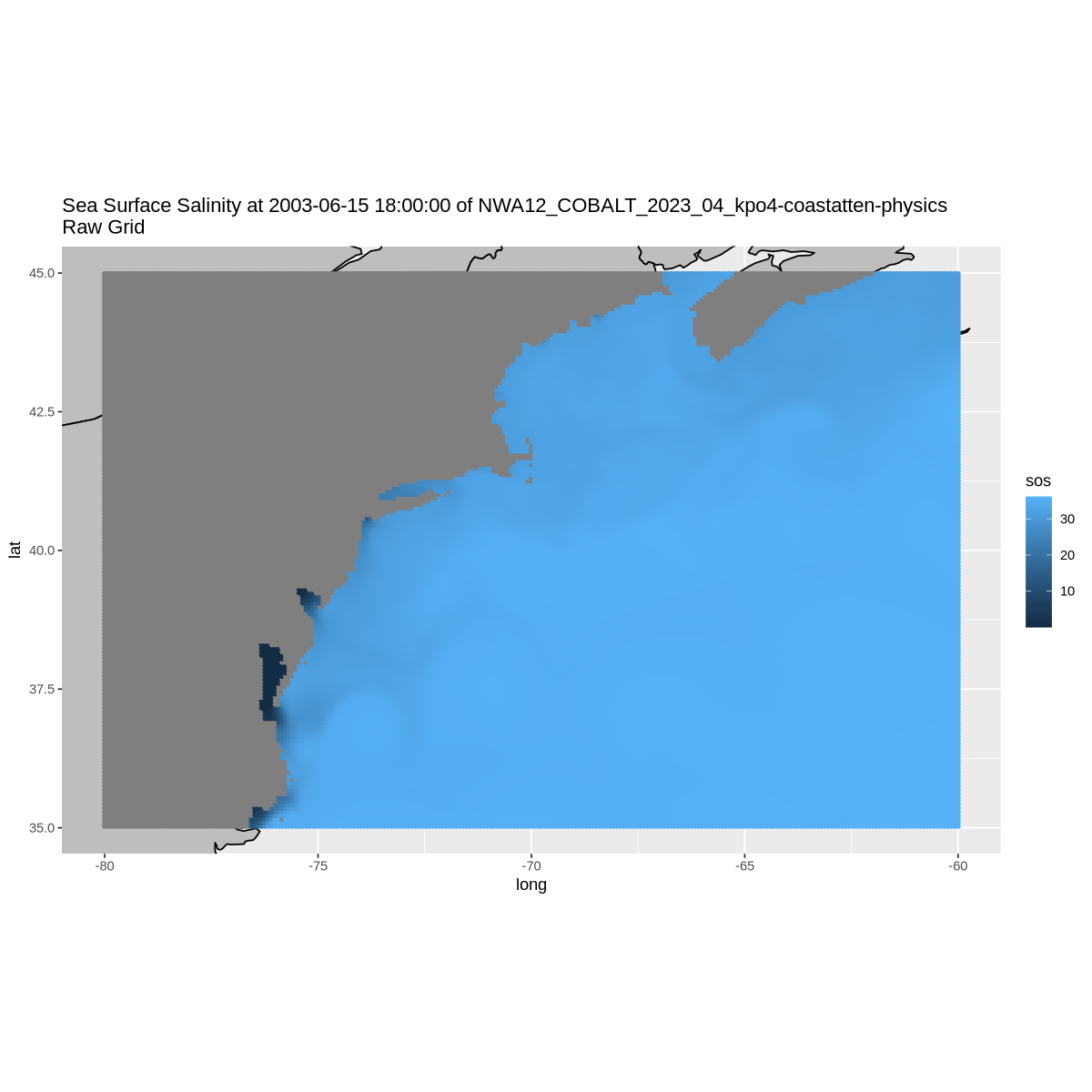
Accessing the data on the original model grid#
The original model grid is explained in detail at the beginning of the cookbook. Understanding where the data are located on the earth requires you to merge the raw grid data file with the grid description. We’ll get both the data and the grid from the cloud storage just as we did in the example above and merge them using xarray, then we’ll convert them to a data.frame for plotting (or processing) in R.
N.B. we use the AWS cloud storage here. We used the Google Cloud Storage above. You can use either, but if you are computing in a cloud environment you’ll get better performance if you use the same cloud.
N.B. The “bucket” names are slightly different
N.B. Additional parameters (remote_options and target_options) are needed to let AWS know that the access does not require any credentials and could be done anonymously.
params = list(anon = TRUE)
fs <- fsspec$filesystem('reference',
remote_protocol='s3',
fo='s3://noaa-oar-cefi-regional-mom6-pds/northwest_atlantic/full_domain/hindcast/monthly/raw/r20230520/sos.nwa.full.hcast.monthly.raw.r20230520.199301-201912.json',
remote_options=params,
target_options=params
)
m <- fs$get_mapper()
dataset <- xr$open_dataset(m, engine='zarr', consolidated=FALSE)
fsg <- fsspec$filesystem('reference',
remote_protocol='s3',
fo='s3://noaa-oar-cefi-regional-mom6-pds/northwest_atlantic/full_domain/hindcast/monthly/raw/r20230520/ocean_static.json',
remote_options=params,
target_options=params
)
gm <- fsg$get_mapper()
dataset <- xr$open_dataset(m, engine='zarr', consolidated=FALSE)
grid <- xr$open_dataset(gm, engine='zarr', consolidated=FALSE)
Slicing the data#
Here, we get one month slice from the data set. We took June 2003 in this case.
slice = dataset$sel(time='2003-06')
title = slice$attrs$title
long_name = slice$sos$long_name
datetime = slice$time$values
slice
<xarray.Dataset> Size: 3MB
Dimensions: (time: 1, nv: 2, yh: 845, xh: 775)
Coordinates:
* nv (nv) float64 16B 1.0 2.0
* time (time) datetime64[ns] 8B 2003-06-16
* xh (xh) float64 6kB -98.0 -97.92 -97.84 ... -36.24 -36.16 -36.08
* yh (yh) float64 7kB 5.273 5.352 5.432 5.511 ... 51.9 51.91 51.93
Data variables:
average_DT (time) timedelta64[ns] 8B ...
average_T1 (time) datetime64[ns] 8B ...
average_T2 (time) datetime64[ns] 8B ...
sos (time, yh, xh) float32 3MB ...
time_bnds (time, nv) datetime64[ns] 16B ...
Attributes: (12/27)
NCO: netCDF Operators version 5.0.1 (Homepage = http:/...
NumFilesInSet: 1
associated_files: areacello: 19930101.ocean_static.nc
cefi_archive_version: /archive/acr/fre/NWA/2023_04/NWA12_COBALT_2023_04...
cefi_aux: N/A
cefi_data_doi: 10.5281/zenodo.7893386
... ...
cefi_subdomain: full
cefi_variable: sos
external_variables: areacello
grid_tile: N/A
grid_type: regular
title: NWA12_COBALT_2023_04_kpo4-coastatten-physics
lon <- grid$geolon$values
lat <- grid$geolat$values
We’re using the lat and lon values from the static grid file to pair with each data value we read from the raw grid file to create a data.frame with lon,lat,sos
slice <- slice$transpose('xh', 'yh', 'time', 'nv')
X <- as.vector(t(lon))
Y <- as.vector(t(lat))
data <- as.vector(t(matrix(slice$sos$values)))
df <- data.frame(
"lon" = X,
"lat" = Y,
"sos" = data
)
sub = filter(df, lat>35)
sub = filter(sub, lat<45)
sub = filter(sub, lon>=-80)
sub = filter(sub, lon<=-60)
sub
| lon | lat | sos |
|---|---|---|
| <dbl> | <dbl> | <dbl> |
| -80.00000 | 35.02885 | NaN |
| -79.92001 | 35.02885 | NaN |
| -79.84000 | 35.02885 | NaN |
| -79.76001 | 35.02885 | NaN |
| -79.67999 | 35.02885 | NaN |
| -79.60001 | 35.02885 | NaN |
| -79.51999 | 35.02885 | NaN |
| -79.44000 | 35.02885 | NaN |
| -79.35999 | 35.02885 | NaN |
| -79.28000 | 35.02885 | NaN |
| -79.20001 | 35.02885 | NaN |
| -79.12000 | 35.02885 | NaN |
| -79.04001 | 35.02885 | NaN |
| -78.95999 | 35.02885 | NaN |
| -78.88000 | 35.02885 | NaN |
| -78.79999 | 35.02885 | NaN |
| -78.72000 | 35.02885 | NaN |
| -78.64001 | 35.02885 | NaN |
| -78.56000 | 35.02885 | NaN |
| -78.48001 | 35.02885 | NaN |
| -78.39999 | 35.02885 | NaN |
| -78.32001 | 35.02885 | NaN |
| -78.23999 | 35.02885 | NaN |
| -78.16000 | 35.02885 | NaN |
| -78.07999 | 35.02885 | NaN |
| -78.00000 | 35.02885 | NaN |
| -77.92001 | 35.02885 | NaN |
| -77.84000 | 35.02885 | NaN |
| -77.76001 | 35.02885 | NaN |
| -77.67999 | 35.02885 | NaN |
| ⋮ | ⋮ | ⋮ |
| -62.32001 | 44.98657 | NaN |
| -62.23999 | 44.98657 | NaN |
| -62.16000 | 44.98657 | NaN |
| -62.07999 | 44.98657 | NaN |
| -62.00000 | 44.98657 | NaN |
| -61.92001 | 44.98657 | 30.98845 |
| -61.84000 | 44.98657 | 31.01529 |
| -61.76001 | 44.98657 | 31.11183 |
| -61.67999 | 44.98657 | 31.18510 |
| -61.60001 | 44.98657 | 31.26443 |
| -61.51999 | 44.98657 | 31.35068 |
| -61.44000 | 44.98657 | 31.43041 |
| -61.35999 | 44.98657 | 31.50238 |
| -61.28000 | 44.98657 | 31.57698 |
| -61.20001 | 44.98657 | 31.64444 |
| -61.12000 | 44.98657 | 31.69162 |
| -61.04001 | 44.98657 | 31.72362 |
| -60.95999 | 44.98657 | 31.73899 |
| -60.88000 | 44.98657 | 31.73177 |
| -60.79999 | 44.98657 | 31.70110 |
| -60.72000 | 44.98657 | 31.64692 |
| -60.64001 | 44.98657 | 31.58435 |
| -60.56000 | 44.98657 | 31.52341 |
| -60.48001 | 44.98657 | 31.47704 |
| -60.39999 | 44.98657 | 31.45421 |
| -60.32001 | 44.98657 | 31.44486 |
| -60.23999 | 44.98657 | 31.43628 |
| -60.16000 | 44.98657 | 31.42496 |
| -60.07999 | 44.98657 | 31.41590 |
| -60.00000 | 44.98657 | 31.42198 |
options(repr.plot.width = 10, repr.plot.height = 10)
ylim <- c( min(sub$lat), max(sub$lat) )
xlim <- c( min(sub$lon), max(sub$lon) )
w <- map_data( 'world', ylim = ylim, xlim = xlim )
p = ggplot() +
geom_polygon(data = w, aes(x=long, y = lat, group = group), fill = "grey", color = "black") +
coord_fixed(1.3, xlim = xlim, ylim = ylim) +
geom_point(data = sub, aes(color = sos, y=lat, x=lon), size=1) +
labs(title = paste(long_name, 'at', datetime, 'of', title, '\nRaw Grid'))
p